HyperLogLog is a beautiful algorithm that makes me hyped by even just learning it (partially because of its name).
This simple but extremely powerful algorithm aims to answer a question: How to estimate the number of unique values (aka cardinality) within a very large dataset? This question is called Count-distinct problem in Computer Science or Cardinality Estimation Problem in Applied Mathematics. We will call it Cardinality Estimation Problem in this article because it sounds more impressive.
But before we understand how HyperLogLog solves the cardinality estimation problem, we first have to know why we need HyperLogLog to solve this problem.
Photo by Markus Spiske on Unsplash
How Many Unique Visitors in the Exhibition?
Imagine that you are hosting an art exhibition. Your job is standing at the entrance and counting how many unique visitors so far using only pen and paper. Given that a small error in counting is acceptable, how can you achieve the task?
One solution can be: writing down all the visitors’ full names and just check how many unique names on it.
But what if you get thousands of visitors a day? Do you have enough papers? And will you be happy with writing down thousands of names?
Another solution can be: instead of writing down names, you can write down the last 6 digits of their phone number.
Nevertheless, it still requires a lot of work. Right now, let's make the task even harder. Can you count the number in real-time or near real-time? And to make it exponentially harder: can you achieve the task only by finger-counting?
Flajolet-Martin Algorithm
Yes, you can. You can count thousands of unique visitors in real-time only by finger-counting.
Our friends Philippe Flajolet and G. Nigel Martin introduced a brilliant algorithm in their 1984 paper "Probabilistic Counting Algorithms for Data Base Applications" that may help us solve this task. [1]
The solution is: just use your finger to keep track of the longest sequence of leading zeroes you have seen in those 6 digits of phone numbers.
For example, if you get 532885, the longest sequence of zeroes is 0.
The next you get 042311, the longest sequence now comes to 1.
When you see more than 10 people, the longest sequence will more likely be 1. Similarly, when you see more than 100 people, the longest sequence will more likely be 2.
It's easy to see that in random data, a sequence of k zero will occur once in every 10ᴷ elements, on average.
Now, imagine that your longest sequence right now is 5, chances are that you have seen more than 1,000 people to find someone's last 6 digits of phone number start with 00000.
You get the idea.
Based on probability, the estimation of how many unique visitors will be close to 10ᴸ, given L is the longest sequence of leading zeroes you found in all the numbers.
In fact, in our friends’ 1984 article, they hashed the elements first to get more uniformly distributed binary outputs. For example, they may hash an element x1 to 010001 and another x2 to 101000. Therefore, phone numbers that aren't uniformly distributed due to some pattern like area code can also be estimated correctly. Also, because they turned the output into a binary bit array, right now the estimation of cardinalities is 2ᴸ.

However, statistical analysis shows that 2ᴸ actually introduces a predictable bias. So they add a correction factor ϕ ≈ 0.77351 to complete the ultimate formula: 2ᴸ / ϕ.

This algorithm is called Flajolet-Martin Algorithm. What a name! Later we will see the importance of naming and how Flajolet actually improved his naming skills.
How to improve: LogLog
I know you may think that the estimation seems to be not that robust and reliable. Imagine that the hash value you get from the very first element turns out to be 000000010 — jackpot! In real life, some outliers in our data can screw up our estimation. Of course, our friend Flajolet knew that too.
How to make our estimation less influenced by the outliers? One obvious solution is to repeat the Flajolet-Martin Algorithm with multiple independent hash functions and average all the results. For example, if we obtain the longest sequence of leading zeroes using m different hash functions, here we denote the value of the longest sequence of leading zeroes as L₁, L₂, …, Lₘ, , then our final estimation becomes m * 2^((L₁+…+Lₘ)/m).
However, hashing an input with multiple hashing functions can be quite computationally expensive. Therefore, our friend Flajolet and his new friend Marianne Durand came up with a workaround: how about using one single hash function and using part of its output to split the value into many different buckets? To split the value into buckets, they just use the first few bits of the hash value as the index of the buckets and count the longest sequence of leading zeroes based on what’s left.
For example, if we want to have four buckets, we can use the first two bits of the hash value output as the index of the buckets. Assuming we have four elements and get the hash values of them:
Hash(x1) = 100101: the 2nd (10) bucket right now with longest sequence of leading zeroes = 1 (0101)
Hash(x2) = 010011: the 1st (01) bucket right now with longest sequence of leading zeroes = 2 (0011)
Hash(x3) = 001111: the 0th (00) bucket right now with longest sequence of leading zeroes = 0 (1111)
Hash(x4) = 110101: the 3rd (11) bucket right now with longest sequence of leading zeroes = 1 (0101)
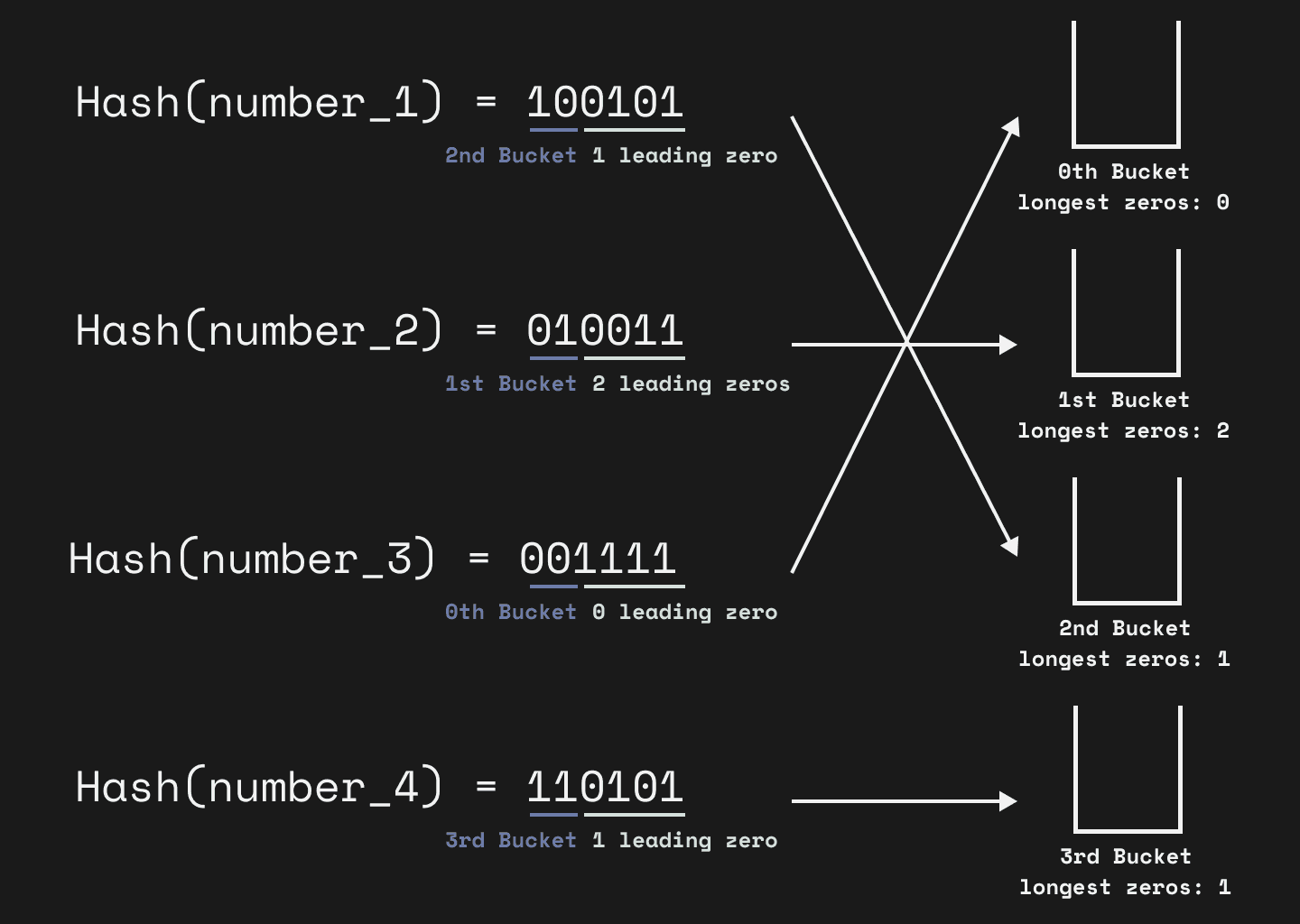
The average of the longest leading zeros of all buckets is (0+2+1+1)/4 = 1. Therefore, our estimation here is 4 * 2^1. It is not close to the true value because here we only have very few samples, but you get the idea.
LogLog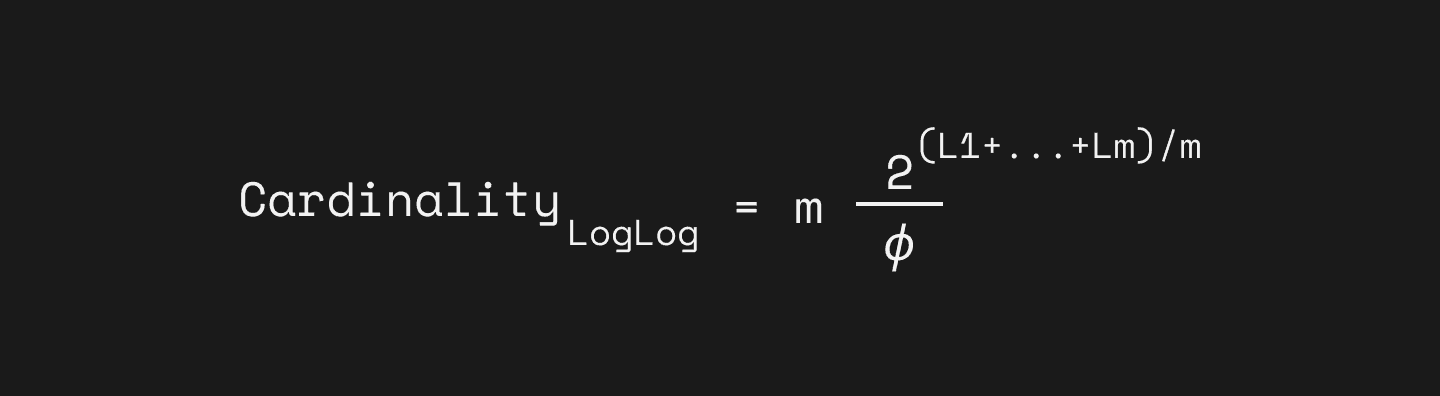
You can find more detail about the correction factor ϕ for LogLog in their 2003 paper “Loglog Counting of Large Cardinalities”.[2] (They denoted the correction factor as α in the original paper.)
So this is LogLog, averaging the estimator to decrease the variance. The standard error of LogLog is 1.3/√m, given m is the number of buckets.
Can we get a better name: SuperLogLog
After coming up with Flajolet-Martin Algorithm and LogLog, our friend Flajolet is unstoppable in terms of tackling the cardinality estimation problem. He decided to push to the extreme of this problem.
In the same paper [2] as they introduced LogLog, Durand and Flajolet found out that the accuracy can be largely improved by throwing out the largest values they got from those baskets before averaging them.
To be more specific, when collecting the values from the buckets, we can retain the 70 percent smallest values and discarding the rest for averaging. By doing so, the accuracy is improved from 1.3/√m to 1.05/√m. What a miracle! And here they decided to give this method a superior name: SuperLogLog.
SuperLogLog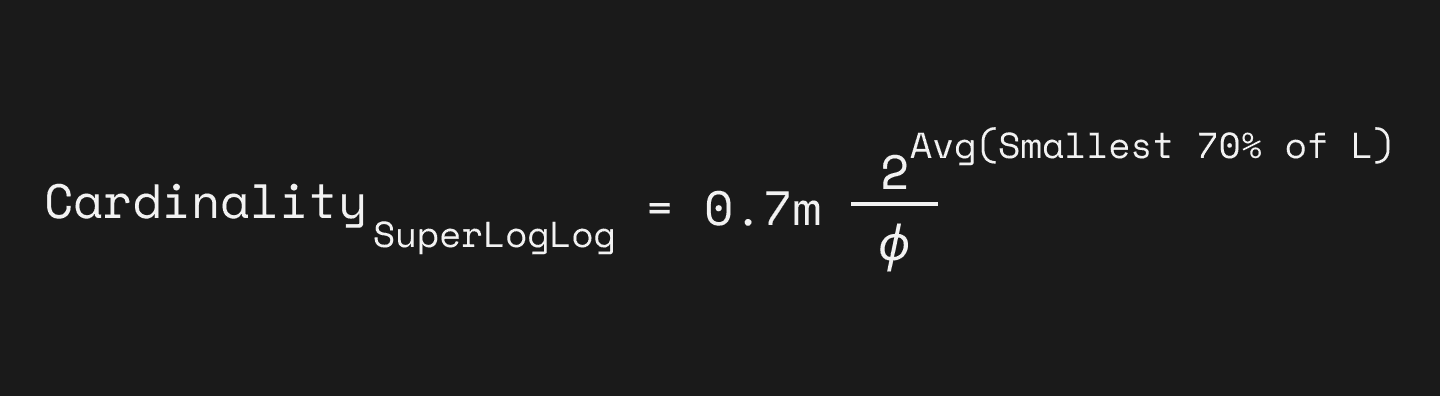
The Ultimate HYPE: HyperLogLog
In 2007, our dear friend Flajolet finally found out his ultimate solution for the cardinality estimation problem. This solution is HyperLogLog, which he referred to as the "near-optimal cardinality estimation algorithm".[3] The idea behind it is very simple: instead of using geometric mean to average the result we got from LogLog, we can use harmonic mean!
The harmonic mean is the reciprocal of the average of the reciprocals.
Reciprocal just means 1/value. Therefore, the formula of harmonic mean is n / (1/a + 1/b + 1/c + ...).
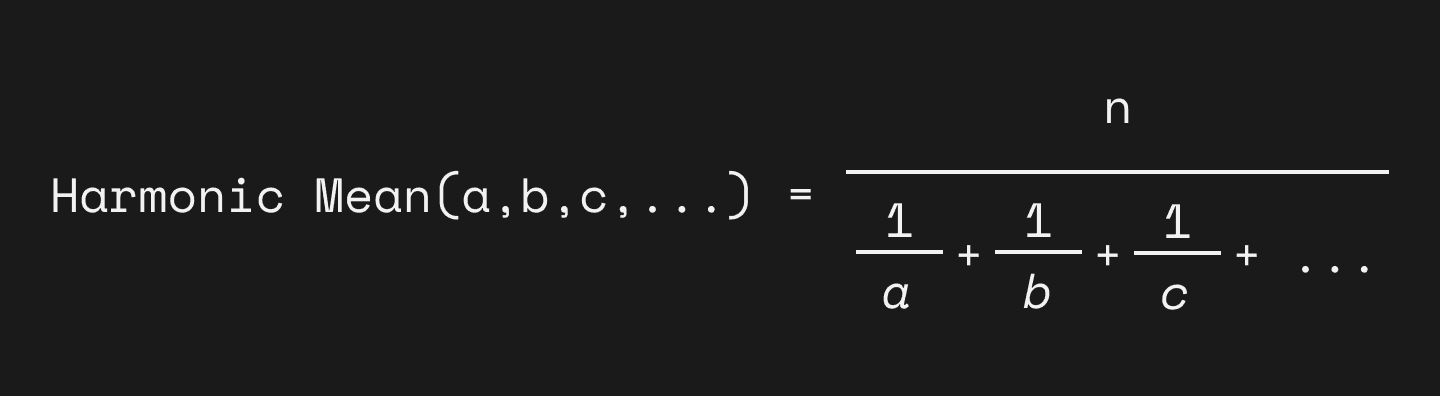
For example, the harmonic mean of 1, 2, 4 is
3 / (1/1 + 1/2 + 1/4) = 3 / (1.75) = 1.714
Why using Harmonic means? Because it is good at handling large outliers. For example, considering the harmonic mean of 2, 4, 6, 100:
4 / (1/2 + 1/4 + 1/6 + 1/100) = 4.32
The large outlier 100 here is being ignored because we only use the reciprocal of it. Therefore, we got an averaging method that can be less influenced by large outliers.

Again, you can find more detail about the correction factor ϕ for HyperLogLog in their 2007 paper “HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm”.[3]
By using harmonic mean instead of geometric mean used in LogLog and only using 70 percent smallest values in SuperLogLog, HyperLogLog achieve an error rate of 1.04/√m, the lowest among all.
HyperLogLog in Real-world Application
Now we understand how HyperLogLog works. This algorithm can estimate the number of unique values within a very large dataset using little memory and time. In fact, it can estimate cardinalities beyond 10^9 with a 2% standard error while only using 1.5kb memory. Where can we find HyperLogLog in the wild?
One example is how Reddit counts how many unique views of a post. In the article View Counting at Reddit, they elaborated that how HyperLogLog satisfied their four requirements for counting views:
- Counts must be real time or near-real time. No daily or hourly aggregates.
- Each user must only be counted once within a short time window.
- The displayed count must be within a few percentage points of the actual tally.
- The system must be able to run at production scale and process events within a few seconds of their occurrence.
Some other great examples are databases and data warehouses that have to cope with petabyte-scale data. For supporting an efficient count unique function for data query, those applications use HyperLogLog. Such examples include Redis, Amazon Redshift, Facebook Presto, BigQuery, and Apache Druid.
Conclusion
That’s it. In this article, we see the development and improvement of the ideas from paper to paper. We learn about the Count-distinct problem (Cardinality estimation problem), our friend Philippe Flajolet and his many friends, Flajolet–Martin algorithm, LogLog, SuperLogLog, HyperLogLog algorithm, and their applications.
As a side note, in the original paper, instead of counting the longest sequence of leading zeroes, Flajolet–Martin algorithm actually counts the position of the least-significant bit in the binary. Furthermore, LogLog, SuperLogLog and HyperLogLog actually count the position of the leftmost 1 (so it is 1 + the number of leading 0's). I simplified those details for clarity, but the concepts are all quite similar. Interested readers can read the original papers for more accurate details.
Before you leave, you can try to answer these questions on your own as a review of the algorithm.
- What’s the problem?
- Why should we use the algorithm?
- How the algorithm solves the problem?
- Where the algorithm is used?
Hope you enjoy the article and thanks for reading.
References
- Flajolet, Philippe; Martin, G. Nigel (1985). "Probabilistic counting algorithms for data base applications"
- Durand, Marianne; Flajolet, Philippe (2003). "Loglog Counting of Large Cardinalities"
- Flajolet, Philippe; Fusy, Éric; Gandouet, Olivier; Meunier, Frédéric (2007). HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm
Thanks to Colin Gladue and Ting-Wei (Tiffany) Chiang for reading the draft of this.